Python is a wonderful language. Other than being simple to learn and fast to write, it’s also very powerful thanks to its huge ecosystem. In fact, it has so many features that it’s easy to miss some good ones. In this article I’m going to show you 3 great Python tricks you may have missed:
tqdm
If you ever use Python to do some sort of elaboration, chances are you find yourself writing a for loop, iterating through a list of items to process each one them. For example:
for item in range(10000000):
result = item * 2
But how could you track the status of the process if the code took more than a few seconds to complete? You probably would start adding some prints:
for item in range(10000000):
print("Processing:", item)
result = item * 2
print("Done!")
While this is a working solution, a smarter approach would be using tqdm.
tqdm is a Python library that makes it easy to show a smart progress bar for almost any kind of loop processing. Let’s see an example:
The first thing to do is installing the package using pip:
pip install tqdm
Then we can use it in our code by simply wrapping the iterable inside the tqdm() call:
from tqdm import tqdm
for item in tqdm(range(10000000)):
result = item * 2
Now if you execute this code, you will see a nice progress bar appear in your terminal.
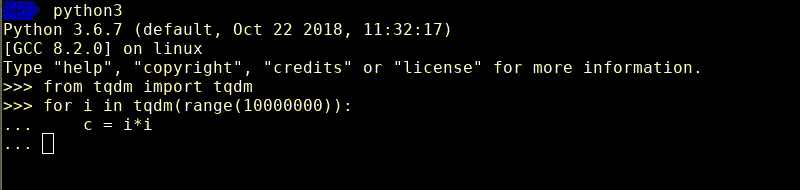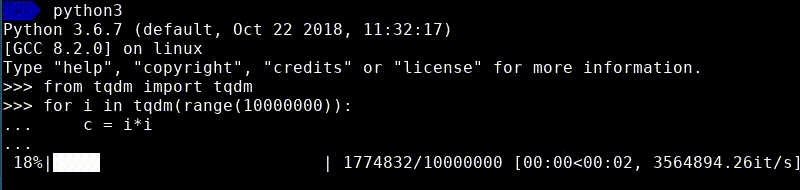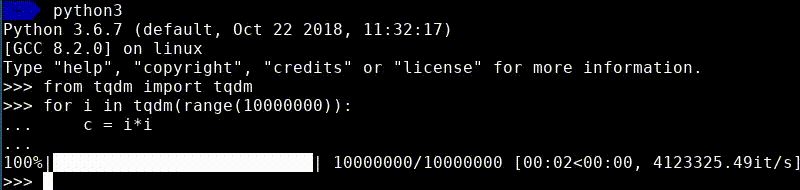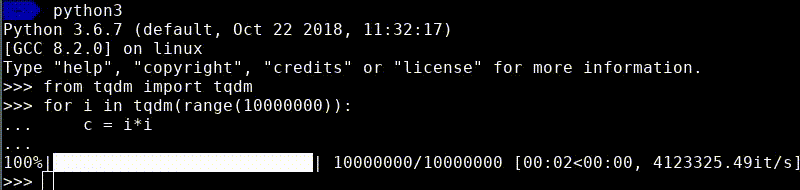
As you can see, besides the progress, it also shows the speed and the expected remaining time. The great thing is that you can use tqdm with any iterable, making it trivial to improve your existing scripts!
This library has many more features, so if you haven’t already, check out the official documentation.
defaultdict
One of the best things about Python is its simplicity. Once you know the basic structures of the language, you can immediately start writing code with it. While being a great aspect, it sometimes causes people to miss some neat data structures, such as defaultdict. Let’s see where it can be useful with an example:
Given a text, you want to group words by their initials. The structure we’re looking for here is a dictionary of lists, having the initials as key and a list of words as value, something like this:
{
"a": ["all", "although", "average"],
"b": ["best", "both"],
...
}
So you start writing code, and you come up with something like this:
text = "a long text but very interesting and fun"
data = {}
# Cycle through each word, appending it to the correct list
for word in text.split(" "):
data[word[0]].append(word)
But then you get the following error:
Traceback (most recent call last):
File "main.py", line 5, in <module>
data[word[0]].append(word)
KeyError: 'a'
Of course, the first time you see an initial, the associated list is not initialized. Easy to fix, we must first check if the key is present and, if not, initialize the list:
text = 'a long text but very interesting and fun'
data = {}
# Cycle through each word, appending it to the correct list
for word in text.split(" "):
if word[0] in data:
data[word[0]].append(word)
else:
data[word[0]] = [word]
And now it is working, but the code became bloated with the check. defaultdict is meant to solve that problem. In particular, we can specify the default value of a key that has never been accessed, such as an empty list. The code now becomes:
from collections import defaultdict
text = 'a long text but very interesting and fun'
data = defaultdict(list)
# Cycle through each word, appending it to the correct list
for word in text.split(" "):
data[word[0]].append(word)
As you can see, we completely removed the check, and the code is still working! This is possible because we replaced the dictionary with a defaultdict, specifying list as the default value ( meaning an empty list ).
A similar problem arises when we want to count the number of occurrences of each word in a text. While we could use a defaultdict with 0 as the default value, there’s a class made exactly for that purpose:
Counter
The Counter class was specifically made to solve those kinds of problems, adding also a couple of extra goodies to the mix. For example:
We want to count the number of occurrences of each word in a text. With the Counter class, this is easily accomplished:
from collections import Counter
text = 'and another long text but interesting and fun'
c = Counter()
for word in text.split(" "):
c[word] += 1
print(c)
Actually we can do even better using the Counter’s constructor:
from collections import Counter
text = 'and another long text but interesting and fun'
c = Counter(text.split(" "))
print(c)
At this point, we can use some neat features such as the most_common method:
# Print the 3 most common words, along with their count
print(c.most_common(3))
Conclusion
There are many other great tools hidden under the surface and I recommend you to check out the official documentation of the collections package to see many more.
